
Data science is considered one of the hottest jobs right now, and for good reason. More than 2.5 quintillions (18 zeros) bytes of data are created every day! Data science jobs ranked on both Glassdoor’s list of best jobs in America 2020 and LinkedIn’s Emerging Jobs Report 2020.
With a median salary of $107,801 and a flourishing future, a lot of job-seekers are looking into the field of data science.
With the increasing demand for data scientists, there is a shortage of quality data science skill sets because becoming a data scientist is no easy task. The role is like a detective job as you try to detect meaningful information from raw data and come out with the best predictive models.
Data scientists need to be skilled in mathematics, statistics, machine learning, and data visualizations with Python or R programming. Various courses and online videos don’t teach all of the industry requirements. So, there are some common mistakes new data scientists can make.

10 of the Most Common Data Science Mistakes
Let’s look at some of the most common data science mistakes to learn from them and help people interested in the field grow in their career.
1. Analysis Without a Question/Plan
Analysis needs a direction and plan to proceed. Data science problems begin with a well-defined objective. Sometimes, data scientists jump directly into analysis and modeling without thinking about the question they’re trying to answer first.
For data scientists, the question they are trying to answer isn’t “what” but “why.” To answer “why” questions, data scientists need to be clear on what they want to achieve with their analysis.
Here’s an example:
As a data scientist, you need to know if the given problem is a supervised or unsupervised ML problem because further analysis and planning are done accordingly. Analyzing without knowing the type of problem first will lead nowhere.
Data scientists who don’t know what they actually want end up with analysis results that they don’t want. Always be ready with well-defined questions to hit your data science goal.
2. Lack of Data Annotations and Continuing to Use Corrupted Data
60% of a data scientist’s time is spent preparing and cleaning data. Although this task is the least enjoyable, it’s an important step. All future operations need to be performed on clean data, which is the base of a machine learning problem.
Data annotation is labeling data correctly and happens in the pre-processing step for supervised machine learning. Data scientists need a large amount of correctly-annotated data to train machine learning models, especially in image and video data.
Working on corrupted data without data annotations is like baking a cake without the correct ingredients. Will your cake come out fluffy, soft, and tasty? No!
Below is an example of corrupted data:
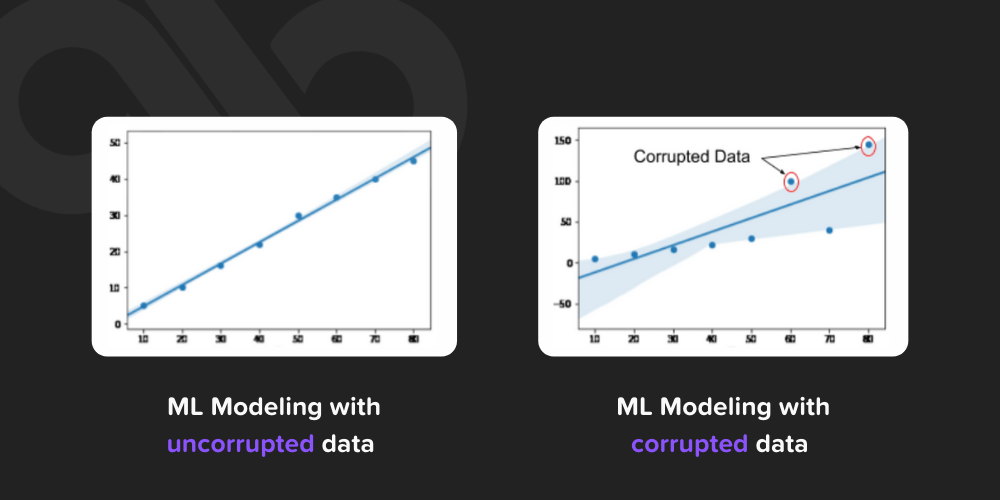
Corrupted data leads to incorrect model building as we can see in the above image. Data needs to be cleaned without errors and outliers for correct model building.
3. Not Focusing on Analysis
Data visualization and analyses are the most interesting parts of being a data scientist. In competitions, some data scientists will jump directly to predictive modeling, but this approach won’t solve any machine learning problems accurately in real world scenarios. Data scientists need to dig deeper into the data insights.
By spending more time with the data analysis, studying trends and patterns, and asking questions, we can create beautiful stories out of the data.
Here’s an example:
Let’s say we have a dataset with many features, but all the features are not always important for modeling. The analysis helps in selecting important features for modeling and dropping features that don’t impact the output predictions. With this information, it will be easy to implement machine learning models on the important features and the predictions will be more accurate.
4. Assuming Correlation Implies Causation
Correlation does not imply causation. Correlation is a statistical technique that refers to how two variables change together (ex: if there is a change in variable x then there will be the change in y). When x increases, y increases, which means that x and y are correlated.
But, it doesn’t always mean that x causes y or y causes x. Sometimes, illogical analysis says x causes y because x and y are correlated, but this isn’t always true.
Let’s look at an example:
After launching a new feature in an app, the customer retention of the app increases. New features and customer retention might be correlated, but that doesn’t mean that the new feature caused customer retention. There might be many other factors for customer retention but both results are related.
Don’t jump to the conclusion of causation too quickly after finding correlation.
5. Not Considering all the Useful Datasets While Building the Model
There might be multiple datasets to a problem and a good data scientist needs to consider all different datasets and try to link the information between them. Sometimes information is divided among various datasets to make it more readable. It’s a data scientist’s job to create a link, understand, and draw a correct picture of the data set while building the model.
Let’s look at an example:
Generally, in time series analysis, we have yearly or monthly datasets. Machine learning models need to learn from all datasets for accurate predictive modeling. Similarly, there are datasets with lots of text data in one dataset and other features related to the text in other datasets. Consolidating these datasets to gain a correct understanding of the data is important.
Never neglect or ignore any information. In the case of the small dataset, upsampling and augmentation work well to increase the size of the dataset. On bigger datasets, machine learning models and deep learning models work very well.

6. Using the Same Functions for Different Problems
Doctors don’t prescribe the same medicine for every disease, we don’t use the same key to unlock every door, and we can’t solve every problem in life using the same solution.
We also can’t apply the same functions for different problems because this would only be theoretical knowledge. Some amateur data scientists may be tempted to implement the same functions, tools, and courses to every problem.
Every problem is unique, so its solution should be, as well. There are so many types of data we have like text data, voice data, image data, numeric data, time-series data, etc and they all need to be handled differently. Just like we have specific libraries in machine learning, we have different NLP libraries like NLTK, Spacy, and more. For images and videos, we use a Convolutional neural network. For time-series analysis we have ARIMA.
Similarly, there are many functions and algorithms in the Scikit-Learn library. Data scientists can’t use NLTK libraries for computer vision problems and vice versa.
7. Focusing Too Much on Accuracy
Accuracy is not the only measure for a good model. The client doesn’t want a black-box model that only gives good accuracy. Accuracy is good, but it’s not everything.
Data scientists should explain how the model reaches accuracy, which features play an important role, why they chose a particular algorithm, the behavior of some different algorithms, and more. Otherwise, the client will reject your model.
Also, parameters of the live production unit should be taken into consideration while developing a model. Otherwise, the work will be a waste and it may need to be redone to match the live environment configurations.
For example, we have an imbalanced dataset of 1000 data points, out of which 900 are negative and 100 are positive. And, our model predicts all data points to be negative. It means out of 1000, 900 points are predicted accurately. So, our accuracy will be:

The model is achieving 90% accuracy, but still, the model is a dump model. High accuracy does not always mean a good model.
8. Not Optimizing Your Model with Time and Data Changes
To become a better data scientist, optimizing your model is a must. You won’t get good results with a single go because the model needs to be optimized with time and data changes.
Optimization is at the heart of every machine learning model. Setting optimized values to hyperparameters gives peak performance, which is why you should revisit and optimize your model from time to time based on new data. This data could include customer behavior changes, trends, seasonality, and more. Data science is a cycle of training, evaluating, optimizing, and re-training.
Let’s look at a simple example in our daily lives:
You have a fixed route to get home from the office every day. Your fixed route has a stadium in-between. Switching to a new route to get home on a game day will save you time. This new route is an optimization that you made.
9. Lack of Consistent Model Validation
It is a big problem for data scientists when a model works well on training data but it doesn’t fit unseen/new data. This might be a problem of overfitting or underfitting, poor predictions, and poor performance.
These problems happen due to a lack of model validation. Model validation means validating your model on some part of training data which is not being used for training. With the model validation approach, a data scientist can validate model accuracy and optimize the model accordingly to reach its peak potential.
Validation helps reach a balanced training model as shown in the image above.
There are two ways to approach model validation: cross-validation and hyperparameter tuning. Model validation consistency has a crucial impact on the results and helps maintain a bias-variance tradeoff, which is an important property of the model.

10. Not Choosing the Right Tools Considering the Problem at Hand
There are so many algorithms available and sometimes data scientists implement different algorithms without actually understanding the problem. Choosing the right algorithm for a given problem is crucial.
There are many tools, including statistics and probability, exploratory data analysis, data-preprocessing steps, and feature engineering, to understand the problem correctly. Without understanding the requirements and problem at hand, just implementing various algorithms is like driving on the road without knowing the destination. You’ll go nowhere!
Here’s an example:
Data scientists need to segment potential mobile phone customers on the basis of their income. The income brackets are below $800 per month, between $800-$1,500 per month, and above $1,500 per month. For the given problem, clustering algorithms will work. If a new data scientist tries to implement a classification algorithm, it won’t help.
So, choosing the right tools for the problem at hand is very crucial.

Conclusion
Being a data scientist is a journey of learning and evolving with every new problem. Don’t get frightened by these mistakes when starting your career. They will definitely teach you how to handle different machine learning problems practically.
There is popular saying: “mistakes are the stepping stones to learning’. Keep making mistakes, but keep learning from them and never repeat the same mistake twice!