
As humans, we can easily identify emotions in face-to-face conversations, written text, videos, and images. But what if machines could analyze emotions in the same way, and understand the sentiments behind these facial expressions? Well, they may be able to.
Here, we will explain what sentiment analysis is and how machine learning uses it to help with emotion detection.
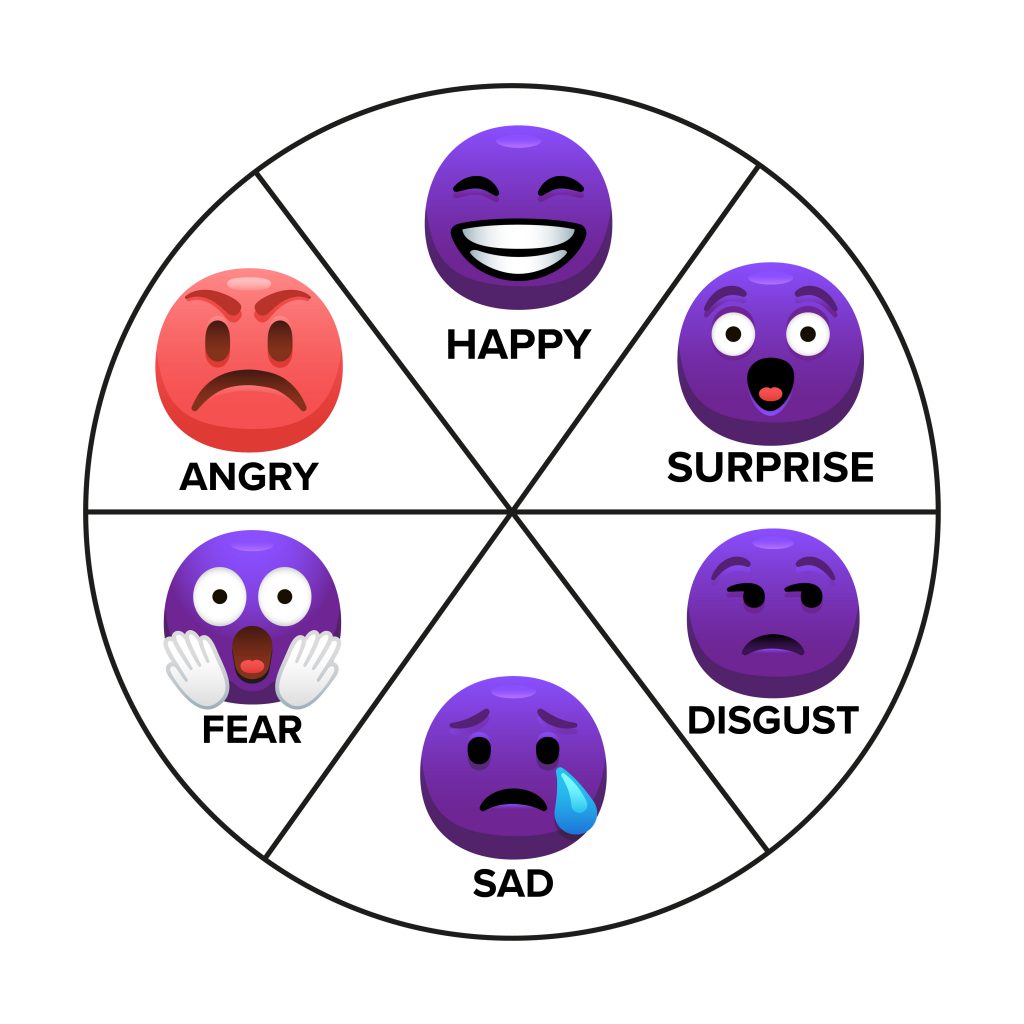
What is Opinion Mining (or Sentiment Analysis)?
Opinion mining, or sentiment analysis, is the field that analyzes human sentiments in various mediums of expression. It refers to the process of identifying and categorizing opinions computationally which are expressed as text, visual, or audio.
Sentiment analysis seeks to analyze a person’s attitude towards a particular thing, topic, or product. Opinion mining is one of the most popular research areas in natural language processing and the demand for this service is increasing as people are expressing more opinions on social media, blogs, review sites, forums, and more.
Sentiment analysis works by examining the six basic emotions: happy, sad, angry, surprise, fear, and disgust. It then labels these emotions as positive, negative, or neutral.
Different Types of Sentiment Analysis
Sentiment analysis applies to almost all businesses because it comes in many different forms. Let’s look at some of the most common types of sentiment analysis.
Textual Data
In an age of digital media, we are constantly surrounded by text on social media, messaging platforms, blogs, review sites, forums, and more. With textual data analysis, we can analyze the sentiment of users.
For example, if a user leaves a review for an instant coffee brand with the headline “instant cup of joy at its best,” sentiment analysis can determine that the review is positive. Negative or neutral reviews can also be classified.
Visual Data
Gone are the days of film cameras and developing pictures. Today, everyone has a smartphone and we click approximately 1.8 billion images every day. Sentiment analysis can examine these images and determine feelings, moods, and emotions fro facial expressions in the picture.
Audio Data
During a conversation, we can easily recognize a person’s emotions using tones and speech patterns. Machine learning can do the same thing by analyzing sentiments using audio data. Areas of audio data sentiment analysis include automatic speech recognition, automated customer care calls, and other audio from social media.

The Benefits of Sentiment Analysis
Sentiment analysis is important for businesses because it can be a checkup on your current customers and new leads. Your customers are people, too, and their beliefs, decisions, actions, and behaviors are all good indicators of their emotions toward your company.
You can use data from your customers’ social media profiles, blogs, and Internet engagement about certain topics to gain an understanding of their sentiments. From there, you can determine which business decisions make sense and which don’t.
For example, imagine that a company launches a new product. Initially, sales are outstanding but they eventually drop. The marketing team wonders what to do to fix the issue. After analyzing product reviews, posts, and conversations about the product, and other information, they learn that there is a small bug that is frustrating customers. They can then take this information to revise the product and increase sales.
How Does Machine Learning Help with Sentiment Analysis?
Using machine learning algorithms, software can predict emotions (sometimes even better than humans!). These emotion detection processes are divided into two main categories: feature extraction and feature classification.
Feature Extraction for Emotion Analysis
Because machine learning algorithms work with concepts if linear algebra and statistics, we have to convert text into numerical data. Machines working with text data is called Natural Language Processing. There are various algorithms to help extract these features from text data.
Bag of Words
Bag of Words is creating a set of unique words from the complete text data, called a corpus. The corresponding vector is created for each document based on the presence of the word and how many times it appears.
Lets, take a sample of 12 twitter comments and their corresponding emotions:
| Text | Emotion |
| I am just so bitter today | Anger |
| Yuck! So creepy | Disgust |
| That’s what I’m afraid of! | Fear |
| Oh! You planned a surprise party for me! | Surprise |
| When we give to others happily, everyone is grateful | Happy |
| The world depresses me | Sadness |
| I don’t talk about politics because people get offended | Anger |
| We have dark, depressing winters | Sadness |
| Wow! What wonderful weather | Surprise |
| I’m nervous for my big test | Fear |
| Ew! Why are you spitting? | Disgust |
| Today is easy, breezy, and beautiful | Happy |
We can then use CountVectorizer in scikit-learn to create Bag of Words in Python.
|
#Import required libraries: import numpy as np import pandas as pd from sklearn.feature_extraction.text import CountVectorizer #Create the dataframe for analysis: d = {‘Text’: [‘I am just so bitter today’, ‘yuck!So creepy’], ‘Emotion’: [‘anger’, ‘disgust’]} sample_data = pd.DataFrame(data=d)
#Create a CountVectorizer object count_vect = CountVectorizer() #Show the features #Show the bag of words output: print(“Bag of words “, count_vect.fit_transform(sample_data[‘Text’]).toarray()) |
You can see that we created a Bag of Words for two documents with seven unique words. These are also called unigrams.
|
>>Feature names [‘am’, ‘bitter’, ‘creepy’, ‘just’, ‘so’, ‘today’, ‘yuck] >>Bag of words [[1, 1, 0, 1, 1, 1, 0], [0, 0, 1, 0, 1, 0, 1]] |
And the vectors created for those two documents look like:
| [1, 1, 0, 1, 1, 1, 0], Here, 1 is for words ‘am’,’bitter’, ’just’, ’so’ and ‘today’ [0, 0, 1, 0, 1, 0, 1], Here, 1 is for word ‘creepy’, ‘so’ and ‘yuck’ |
We can also create bigrams from the text to take conductive words into consideration:
| count_vect = CountVectorizer(ngram_range=(1,2)) final_bigram_counts = count_vect.fit_transform(sample_data[‘Text’]) print(“Feature names “, count_vect.get_feature_names()) |
Unigram and Bigram features together:
| >>Feature names [‘am’, ‘am just’, ‘bitter’, ‘bitter today’, ‘creepy’, ‘just’, ‘just so’, ‘so’, ‘so bitter’, ‘so creepy’, ‘today’, ‘yuck’, ‘yuck so’] |
TF-IDF (Term Frequency- Inverse Document Frequency)
In the Bag of Words approach, we give equal weight to each word. The idea behind the TF-IDF approach is that high-frequency words will be weighted less and low-frequency words, like “yuck” or “creepy” will be given more weight.
TF-IDF is a combination of two terms, Term Frequency and Inverse Document Frequency. They can be calculated as:
| TF-IDF= TF * IDF TF = (Frequency of a word in the document)/(Total words in the document) IDF = Log((Total number of documents)/(Number of documents containing the word)) |
We have TfidfVectorizer in scikit-learn to create TF-IDF features in Python:
|
from sklearn.feature_extraction.text import TfidfVectorizer tf_idf_vect = TfidfVectorizer() print(“Feature names “, tf_idf_vect.get_feature_names()) print(TFIDF_data.toarray()) |
The features created are:
| >> Feature names [‘am’, ‘bitter’, ‘creepy’, ‘just’, ‘so’, ‘today’, ‘yuck’] |
And the TF-IDF vectors created for the documents are:
|
>> [[0.47107781, 0.47107781, 0. , 0.47107781, 0.33517574, 0.47107781, 0. ], |
We can see that in the last vector, more weight is given to the words “creepy” and “yuck” compared to other words.
Singular Value Decomposition(SVD)
In many cases, text data is highly-dimensional, cumbersome, and it takes time to go through this data. SVD is a technique used to reduce the dimensionality of textual data. The idea behind dimensionality reduction is identifying a linear combination of features that have maximum variance and are mutually uncorrelated, such that most of the information remains intact.
We have decomposition.TruncatedSVD library in scikit-learn to implement SVD.
| from sklearn import decomposition t_svd= decomposition.TruncatedSVD() t_svd.n_components = 2 svd_data = t_svd.fit_transform(bow_counts.toarray()) #bow_counts is bag of words of 12 commentsprint(“shape of train data = “, bow_counts.shape) print(“shape of truncated svd = “, svd_data.shape) |
Using SVD, data with 70 dimensions is reduced to two dimensions:
| >>shape of train data = (12, 70) >>shape of truncated svd = (12, 2) |
An output of two dimensions will be like this:
| [-1.03497938e-15, -1.28914109e-15], [ 5.62409454e-16, -3.25668491e-16], [-4.18895299e-17, -6.37741870e-16], [ 1.38039707e-16, 1.00030919e-16], [ 1.05391628e+00, -1.41421356e+00], [ 3.30717793e-16, 4.34989081e-16], [ 5.26958140e-01, 2.82842712e+00], [ 4.03297502e+00, 6.11624764e-15], [-1.06233812e-15, -7.13708706e-16], [ 6.23413241e-16, -2.94874484e-15], [ 5.46559737e-16, 3.48944877e-16], [ 1.67710377e-16, -5.28774143e-16] |
Feature Classification for Emotion Analysis
After feature extraction, we apply different machine learning algorithms for feature classification. We are implementing Logistic Regression, Random Forest, and Neural Networks for classification.
Logistic Regression
Let’s apply logistic regression on Bag of Words using the LogisticRegression library of scikit-learn:
| from sklearn.linear_model import LogisticRegression model_lg = LogisticRegression() model_lg.fit(final_counts, sample_data[‘Emotion’]) |
Next, let’s do some prediction for a new text comment:
| Y = count_vect.transform([“you are sick”]) print(model_lg.predict(Y)) |
>> Output: [‘disgust’]
| Y = count_vect.transform([“no one cares”]) print(model_lg.predict(Y)) |
>> Output: [‘sadness’]
Logistic Regression predicts the new text very well.
Random Forest
Let’s apply the Random Forest algorithm on TF_IDF features using the RandomForestClassifier library of scikit-learn:
| from sklearn.ensemble import RandomForestClassifier rf_clf = RandomForestClassifier() rf_clf.fit(TFIDF_data, data[‘Emotion’]) |
Let’s do some prediction for a new text comment:
| Y = tf_idf_vect.transform([“i am afraid of change”]) print(rf_clf.predict(Y)) |
>> Output: [‘fear’]
| Y = tf_idf_vect.transform([“wow beautiful flowers”]) print(rf_clf.predict(Y)) |
>> Output: [‘happy’]
Random Forest Classification is able to correctly predict new text.
Neural Networks
Neural networks work like our brain cells and the results of neural cells are amazing. We generally have huge datasets with many features.
Like we saw in the feature extraction section, in only 12 comments, we got 70 unique features. Imagine how vast data with millions of comments would be. For such a big data set, neural networks work very well for feature classification. They improve the performance of the model.
Below is a sample code of neural network using Keras:
| from keras.models import Sequential from keras import layers input_dim = final_counts.shape[1] # Number of features model = Sequential() |
We must implement this neural network code to the whole data set to analyze the performance and results.
The Future of Emotional Intelligence
In the above section, we have implemented an emotion analysis of textual data. Similarly, we can implement an emotion analysis of images and voice data. Let’s look at some use cases of these analyses in action.
Facial Expression Recognition
Machines can now read facial expressions in images, as well. Face detection and facial expression recognition can be implemented using deep learning techniques.
Speech Recognition
Artificial intelligence can also analyze our speech patterns. Devices like the Amazon Echo, Google Home, and Siri analyze our speech and take action according to what we say. Deep learning techniques like recurrent neural networks are widely used for speech recognition.
Sentiment analysis of speech can be done on phone conversations, customer care calls, voice search applications, and more. This analysis can help businesses grow as they learn to understand the emotions of their customers.
There is no limit on what can be done with machine learning and artificial intelligence on emotion analysis in the future.